






















[Archives] AVATAR : Entretien avec Andy Jones, superviseur de lanimation au sein de Weta Digital
Article Cinéma du Mardi 03 Avril 2018
Propos recueillis et traduits par Pascal Pinteau
Dès le début de sa carrière, Andy Jones sest spécialisé dans lanimation de personnages 3D hyperréalistes. Après avoir développé les figurants virtuels de TITANIC (1997) et la monstrueuse vedette de GODZILLA (1998), Jones effectue un travail de pionnier sur les premiers clones dhumains de FINAL FANTASY (2001). Il perfectionne cette approche dans LE DERNIER VOL DE LOSIRIS, remarquable court-métrage quil réalise en 2003, et qui est inclus dans la compilation ANIMATRIX. Jones travaille ensuite sur les animations de I ROBOT (2004), CAPTAIN SKY ET LE MONDE DE DEMAIN (2004), ZATHURA, UNE AVENTURE SPATIALE (2005) et SUPERMAN RETURNS (2006), avant dassumer la direction de lanimation dAVATAR.
Vous avez acquis une expérience exceptionnelle dans la création de personnages humains hyperréalistes en 3D, de FINAL FANTASY à AVATAR. Quels sont les progrès les plus significatifs qui ont été accomplis pendant ces huit ans qui séparent les deux films ?
Nous avons beaucoup avancé dans les domaines de lanimation faciale, du rendu de la peau, et du fonctionnement des muscles. Nous sommes plus proches de la réalité anatomique.
Volker Engel nous a expliqué récemment quil avait utilisé un nouveaux logiciel appelé Volume Breaker pour générer semi-automatiquement les effets de destruction des bâtiments dans 2012. Bien quil aime filmer des maquettes, il a admis quelles pourraient vite devenir une technique du passé. Pensez-vous que les nouvelles technologies qui sont développées pour la capture de performance pourraient remplacer en partie ou totalement certaines techniques, comme les maquillages spéciaux, ou lanimation traditionnelle ?
Je crois quil est difficile de répondre dans un sens ou dans lautre à cette question, parce que lon na que très peu de moyens destimer comment les techniques de capture de performance vont évoluer dans le futur. A lheure actuelle, les systèmes que nous employons permettent de recueillir à peu près 80% des données qui servent à animer un personnage 3D. Mais ce qui permet dobtenir un résultat vraiment naturel, ce sont les 20% quapportent les animateurs en complétant ces données. Cela crée une énorme différence. Pour vous donner un exemple précis, quand on observe le résultat dune capture dexpressions faciales « brute » sur un personnage 3D, on voit immédiatement tout ce qui manque pour que cela semble réaliste.
En plus des données recueillies par le système, vous pouviez aussi vous référer à des prises de vues en vidéo des acteurs, pour vérifier quelles étaient leurs postures précises
Oui. Pendant les séances denregistrement en capture de performance, il y avait toujours de 4 à 8 caméras HD qui filmaient la scène sous différents angles. Jim utilisait ces prises de vues vidéo pour préparer le montage de son film, car il ne pouvait pas vraiment utiliser les images brutes obtenues à partir de la capture de mouvement pour faire cela. Les images vidéo représentaient mieux les performances réelles des acteurs. Etant donné que Jim avait déjà choisi ces plans-là, les animateurs pouvaient sy référer en toute confiance, et y puiser les nuances de jeu qui manquaient dans les données de capture, afin de les transférer sur les personnages 3D.
Quelles ont été les plus grandes difficultés à résoudre pour parvenir à animer les personnages et les décors dAVATAR ?
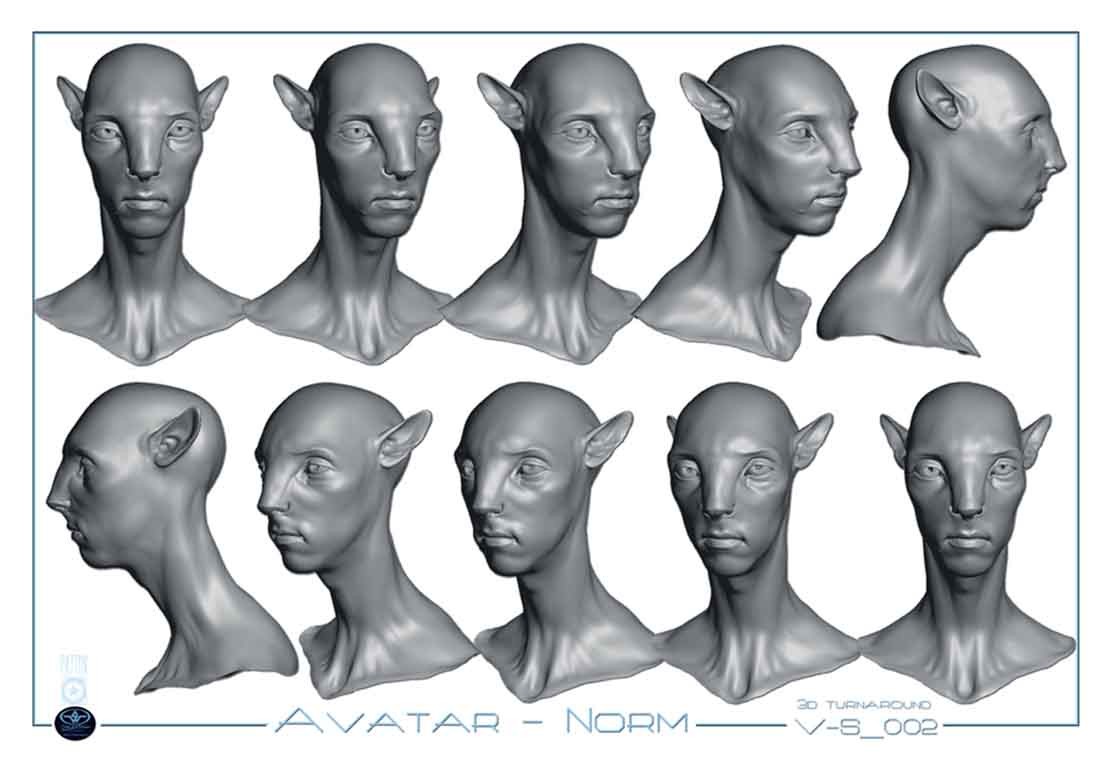
Dabord et avant tout, les expressions faciales des Navis. Depuis le premier jour, cétait la préoccupation principale de Jon Landau et de James Cameron. Ils se demandaient si elles allaient être crédibles et si nous arriverions à reproduire exactement les performances des acteurs. Quand Sam Worthington et Zoe Saldana ont été choisis pour tenir les rôles principaux, nous savions que notre objectif était danimer leurs personnages 3D de manière si réaliste quils soient en mesure de « mener » le film, et de sattirer immédiatement la sympathie des spectateurs. Pour atteindre ce but, il a fallu concevoir des systèmes danimation des expressions très sophistiqués et très précis, afin dimiter parfaitement le comportement des vrais muscles du visage. Nous avons étudié attentivement lanatomie dun visage humain pour réaliser ces travaux. Et quand nous sommes passés à la modélisation et à la conception des animations faciales, nous avons fait des recherches très poussées pour reconstituer en 3D lanatomie des visages de chacun des acteurs principaux. Disons quil fallait connaître les proportions et la localisation de leurs vrais muscles faciaux, et savoir comment ils fonctionnaient, afin de pouvoir les reproduire en 3D sur les personnages de Navi, et obtenir ainsi des expressions qui soient identiques.
Serait-il exact de dire que le modèle 3D de lavatar Navi de Jake a la même forme de crâne et les mêmes masses de muscles faciaux que Sam Worthington ?
Oui, cest globalement cela. En tous cas, même si ce nest pas identique à 100%, cest aussi proche que possible de lanatomie de Sam Worthington, une fois quelle est transposée sur le visage et sur le corps dun Navi. Cependant, comme la silhouette dun Navi est beaucoup plus allongée que celle dun homme, et que Jim tenait à ce que ce peuple soit extrêmement mince, comme des sportifs de haut niveau qui ont moins de 2% de masse graisseuse dans le corps, nous avons dû modifier la musculature de Sam pour construire le personnage de son avatar. Mais nous avons quand même réussi à transposer les mouvements de ses muscles, ainsi que la texture de sa peau. En ce qui concerne les volumes des expressions faciales, comme lamplitude dun sourire et le gonflement simultané des joues, il était géré au final par les animateurs, qui manipulaient les systèmes de coordination des muscles 3D que nous avions mis au point pour gérer semi-automatiquement telle ou telle mimique. Ce quil faut comprendre, cest quun sourire mobilise des dizaines de muscles faciaux, et que lon ne peut pas animer indépendamment, un par un, tous les muscles qui contribuent à animer la peau. Cest la raison pour laquelle Jeff Unay et moi avons passé du temps à développer des commandes semi-automatiques qui permettaient dobtenir des expressions de base, que les animateurs pouvaient ensuite modifier pour obtenir des variantes encore plus proches des expressions des acteurs.
Diriez-vous que la structure musculaire des personnages 3D dAVATAR est lune des plus complexes qui ait été modélisée, jusquà présent ?
Oui, en tous cas, cest ce que nous nous plaisons à croire ! (rires) Le système musculaire est très sophistiqué, et nous permet daccentuer les actions de certains muscles pendant que les personnages bougent ou se battent, ce qui rend leur animation encore plus vivante. Je crois que lon peut dire que les personnages d AVATAR représentent une avancée dans ce domaine. Nous avons beaucoup travaillé en ce sens.
Diriez-vous quil y a pratiquement autant de muscles dans lanatomie dun Navi 3D que dans celle dun véritable être humain ?
Oui, exactement. Nous avons modélisé les Navis en nous référant à lanatomie humaine. Nous avons peut-être éliminé certains muscles mineurs, mais tous les muscles principaux sont bien représentés. Il y en a une quarantaine dans un visage humain, et nous disposons du même nombre de contrôles pour animer les visages des personnages 3D, et pour produire des variantes des expressions principales.
Vous disiez que les séances de capture de performance généraient environ 80% des données danimation. Pourriez-vous nous décrire précisément quels étaient les 20% qui manquaient et que vous deviez compléter ?
Dans la plupart des cas, il sagissait de compléter des nuances de performance qui avaient échappées au système. Disons que les données étaient un peu estompées, si vous voulez. Que les attitudes les plus extrêmes de certaines poses ou de certaines expressions manquaient. Et ce sont justement ces extrêmes qui donnent toute leur vivacité aux gestes et aux expressions des acteurs. Il ne faut pas imaginer que le système de capture de performance est un procédé automatique, que lon actionne en pressant un bouton, et qui anime totalement les personnages. Le système fonctionnait très bien, mais il fallait tout de même corriger, compléter et finaliser lanimation des personnages. Les données générées par les captures produisaient quelquefois des « images-clé » quun animateur naurait jamais utilisé sil avait créé cette scène de A à Z. Il fallait donc les corriger pour obtenir des poses-clés plus naturelles et plus proches de la performance des acteurs. Nous pouvions aussi corriger ces données brutes pour tenir compte de lélasticité et de la souplesse de la peau, toujours dans le but dobtenir un rendu plus fluide et plus réaliste.
Pour être sûr de bien comprendre ce que vous nous expliquez, cela signifie que quand Sam Worthington souriait de manière furtive, le système de capture pouvait « rater » le point le plus extrême de son sourire, et que vous deviez donc le reconstituer par la suite, en vous basant sur les images vidéo de la scène ?
Oui, cest cela : les données extrêmes du sourire pouvaient manquer, ou même des données plus générales de lensemble de son expression, pendant une demi-seconde. Nous avons toujours essayé de respecter les données originales, sauf quand il sagissait de petites erreurs techniques. Notre rôle consistait à les compléter, en nous basant sur lenregistrement vidéo de la performance de lacteur. Les décisions prises par les animateurs ne visaient quà restituer toute la spontanéité du jeu des comédiens.
Vous avez dû animer entièrement les doigts, nest-ce pas ?
Oui. Le système de capture ne pouvait pas les repérer dans lespace, donc nous les avons animés. Un des autres éléments du visage que les animateurs ont pris beaucoup de plaisir à utiliser, ce sont les oreilles des Navis, qui nous aident à refléter leur émotions et leurs pensées.
Lanimation des queues des Navi vous a certainement aidé aussi à exprimer ces émotions
Oui, cétait également intéressant de se servir de ces mouvements-là. Cependant, Jim nous avait dit quil souhaitait que les queues des Navis fonctionnent davantage comme celles des lézards ou des grands fauves, et leur servent davantage de balanciers, pour garder leur équilibre. La queue dun guépard, par exemple, est relativement rigide. Beaucoup plus que celle dun chat domestique, qui reflète directement son état desprit.
Est-ce que certaines données biologiques réelles ont été utilisées pour créer le design des animaux imaginaires de Pandora ?
Oui, nous avons trouvé la plupart de nos références en observant des documentaire animaliers.